Abstract
Cross-lingual summarization (CLS) generates summaries in a target language from texts in a source language, serving as a valuable tool in cross-cultural and global communications. Traditionally achieved through a pipeline of machine translation (MT) and monolingual summarization (MS), CLS tasks are increasingly being explored with various end-to-end mode frameworks without the intermediate outputs. Building on the latest work on end-to-end CLS, we adopt two different approaches to integrating multilingual pre-training into generating Chinese summaries from English source texts: 1) using pre-trained multilingual embeddings only from the translation model mBART, and 2) fine-tuning the entire mBART model on CLS data. The second approach significantly outperforms the baseline model and the first approach, achieving a ROUGE-1 score of 22.37 on the in-distribution evaluation data and 3.82 on an external dataset. These scores surpass the baseline transformer model by 932% and 5,357%, and the first model by 1,002% and 3,720%, respectively.
FYI:
-
The manuscript for this project can be accessed through this link.
-
You can also click this link to check out the conference poster for this paper.
Data
We train all our models on the EN2ZHSUM dataset from, contributed by Zhu et al. with paired English texts and Chinese summaries. The dataset was constructed by first obtaining news articles and their corresponding highlights as sources and targets for monolingual summarization, then using a “round-trip” strategy to translate the summaries to the target language then back to the source language. The translation results were then evaluated using ROUGE to only include the results with high quality in the final dataset. The corpus of EN2ZHSUM contains 370,759 CLS pairs.
For model evaluation, in addition to the test set of EN2ZHSUM, we also use ClidSum, developed by Wang et al., to assess the models’ suitability to be generalized to out-of-distribution dataset. Vastly different from EN2ZHSUM, ClidSum consists of more than 67,000 dialogues and 112,000 annotated summaries. As a result, ClidSum presents an alternate text medium to assess the performance of our models on general CLS tasks. Due to the issue of data availability and the constraint of computing resources, for evaluation we only use 1,000 samples from XMediaSum40k, which is a subset of ClidSum that contains media interviews and their summaries.
Methods
Baseline Model
Our baseline model adopts the Transformer framework, originally designed for sequence-to-sequence translation tasks with strong performance across various language modeling tasks. The baseline transformer consists of an encoder and a decoder each with 6 attention blocks. The embedding dimension is 250,054 and the model dimension is 1,024. The encoder of the model processes English articles first through embedding and positional encoding, and then self-attention and feed-forward layers. The decoder generates summaries in Chinese using cross-attention mechanisms.
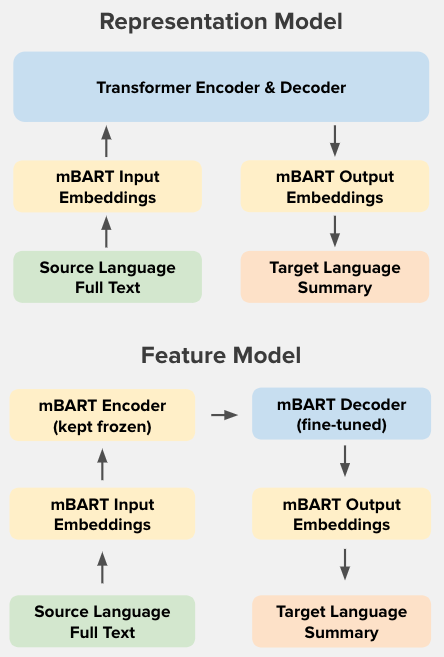
Representation Model
Building on the baseline, we propose our first modeling approach for better cross-lingual understanding and summarization: a Transformer with mBART’s word representations (Representation Model). Specifically, we replace both the input and output embedding layers and positional encoding layers of our baseline model with those of mBART, while other parts of the architecture remain the same. We then train this model using the same set of preprocessed CLS data, while keeping the mBART layers frozen. With this design, we hope to investigate if multilingual word representations from pre-training alone improves model performance. Compared to the baseline model where the embedding layers are initialized randomly and trained from scratch, the Representation Model’s usage of mBART’s pre-trained embedding weights may exhibit better language comprehension abilities from learning from large amounts of natural language.
Feature Model
The Feature Model further integrates multilingual pre-training into CLS. In this architectural design, we fine-tune mBART for the CLS task on our training data. Specifically, we fine-tune the linear layer of mBART to adapt it to the requirements of summarization so that it can generate concise and accurate summaries. Additionally, we also unfreeze two out of ten cross-attention blocks of the mBART decoder. This allows the decoder to recalibrate and learn attention weights with regards to the source texts that are more suited for summarization tasks, which may differ from those required in translation tasks. By doing so, the model is expected to gain a more nuanced understanding of the text and facilitate better content selection and synthesis.
Results
Evaluation results on the test set of EH2ZHSUM and the external dataset ClidSum are shown below. Overall, the Feature Model outperforms the other two significantly, based on both the quantitative and qualitative(i.e. summarization) results.

Conclusion
Our findings demonstrate that the efficacy of models in cross-lingual summarization is significantly enhanced by multilingual pre-training. In particular, employing a greater number of pre-trained weights from many layers of a multilingual model results in a much higher degree of success compared to utilizing only the embeddings. This highlights the importance of knowledge transfer in multilingual pre-training for improving the performance of cross-lingual summarization. By leveraging the comprehensive linguistic knowledge acquired during pre-training, these models can achieve a higher level of success in generating accurate, relevant, and contextually appropriate summaries across different languages.
References
Junnan Zhu, Qian Wang, Yining Wang, Yu Zhou, Jiajun Zhang, Shaonan Wang, and Chengqing Zong. 2019. Ncls: Neural cross-lingual summarization. arXiv preprint arXiv:1909.00156.
Liu, Y., Gu, J., Goyal, N., Li, X., Edunov, S., Ghazvininejad, M., … & Zettlemoyer, L. (2020). Multilingual denoising pre-training for neural machine translation. Transactions of the Association for Computational Linguistics, 8, 726-742.
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi. 2019. Bertscore: Evaluating text generation with bert. arXiv:1904.09675 [cs.CL].
Chin-Yew Lin. 2004. ROUGE: A package for automatic evaluation of summaries. In Text Summarization Branches Out, pages 74–81, Barcelona, Spain. Association for Computational Linguistics.
Lewis, M., Liu, Y., Goyal, N., Ghazvininejad, M., Mohamed, A., Levy, O., … & Zettlemoyer, L. (2019). Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. arXiv preprint arXiv:1910.13461.
Kishore Papineni, Salim Roukos, Todd Ward, and Wei Jing Zhu. 2002. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, ACL ’02, page 311–318, USA. Association for Computational Linguistics.